robots.txt是什麼?robots.txt 教學:robots.txt設定與測試工具SEO必學






Welly SEO 編輯部
2024-02-22更新
# SEO概念
# 技術SEO
robots.txt是什麼?本文將分享SEO robots.txt教學,包含遭到robots.txt封鎖如何解除、robots.txt產生器等,並比較robots.txt vs meta robots,最後教你使用robots.txt測試工具。
快速跳轉目錄
- robots.txt解密|robots.txt用途與注意事項大公開!
- robots.txt教學:robots.txt設定、robots.txt程式代碼內容
- (一)robots.txt程式代碼解析
- (二)robots.txt常見的搜尋引擎名稱
- (三)robots.txt Examples撰寫範例
- (四)robots.txt進階應用
- (五)遭到robots.txt封鎖的頁面該怎麼解除封鎖?
- (六)robots.txt Wordpress-Yoast教學
- (七)3個robots.txt產生器推薦
- 設定robots.txt Google注意事項
- robots.txt vs meta robots|meta robots怎麼寫?
- robots.txt測試工具(robots.txt Tester)怎麼用?Google官方工具教學!
robots.txt解密|robots.txt用途與注意事項大公開!
提升網站SEO排名的前提是Google搜尋引擎要先進行檢索與建立索引,才能讓你的網站進入SEO的戰場。
然而當你的網站遇到以下這3種問題時,可不可以請Google搜尋引擎不要建立索引呢?
- 網頁處在測試或是部分網頁尚未架設完成的狀況
- 內容重複性太高,或是被索引對網站排名沒有幫助
- 網頁內容可能會對SEO排名有不良影響
答案是有的!以下將告訴你robots.txt SEO的用途與注意事項。
(一)robots.txt是什麼?robots.txt用途分享!
robots.txt是一種存放在網頁根目錄的簡易文字檔,用於告知搜尋引擎哪些網站頁面不要檢索。
robots.txt的主要用途是避免網站內龐大的資訊量使網站速度變慢,但仍需注意其無法保證100%不會被搜尋引擎檢索。

以下將針對robots.txt常見問題進行詳細解答:
📍為什麼使用robots.txt之後「仍有機會被搜尋引擎檢索」?
即使使用了robots.txt技術,仍有可能被搜尋引擎檢索,其原因如下:
- 不是所有的搜尋引擎都會支援robots.txt內的指令。
- 對搜尋引擎來說�,robots.txt只是一個參考指令,並沒有強制執行力。
- 不同的搜尋引擎解讀指令的方式也會不同,因此有可能遇到無法解讀的指令便會忽略,導致指令無法實行。
- 如果有外部連結連到robots.txt封鎖的頁面,那搜尋引擎還是會將封鎖的內容檢索。
📍robots.txt指令內容包含哪些?
- 網頁:想要封鎖的網頁,例如重要性較低或重複內容多的網頁
- 媒體:網頁中的照片、影片、音檔
- 資源:網頁中不重要的指令碼或呈現的特定樣式等
這邊先幫大家建立架構與概念,詳細的指令教學會在下一段為大家分享。
📍一定要設定robots.txt指令給Google搜尋引擎嗎?
答案是:不用的!
如果網站內的所有網頁內容都可以被搜尋引擎檢索與建立索引,那麼就不用特別設定robots.txt去封鎖頁面;如果頁面有提交robots.txt,Google搜尋引擎就會「盡量」遵照你的指令,不去收錄該頁面。
robots.txt教學:robots.txt設定、robots.txt程式代碼內容
了解robots.txt是什麼和用途之後,究竟該怎麼設定robots.txt文件?那些複雜難懂的程式代碼分別代表什麼意思呢?
(一)robots.txt程式代碼解析
以下利用表格的方式介紹5種robots.txt程式代碼:
| 程式代碼 | 定義 |
|---|---|
| User-agent | |
| Allow | |
| Disallow | |
| Crawl-delay | |
| Sitemap |

(二)robots.txt常見的搜尋引擎名稱
- Google搜尋引擎:Googlebot
- Googlebot-Image(圖像)
- Googlebot-News(新聞)
- Googlebot-Video(影片)
- Yahoo:Yahoo!Slurp
- Bing:bingbot
- Ahrefs:Ahrefsbot
- 百度:Baiduspider
- ChatGPT:GPTBot
(三)robots.txt Examples撰寫範例
在robots.txt的程式代碼裡,最常被大家搜尋的關鍵字是「robots txt disallow all search engine」,原因是Disallow這個程式代碼主要用於限制搜尋引擎檢索,而多數人會希望所有搜尋引擎不要檢索特定網頁內容,因此會想要搜尋此關鍵字找到程式代碼的答案。
以下將為大家揭秘各種不同robots.txt的目的,讓你一次搞懂程式代碼邏輯!
| robots.txt目的 | robots.txt撰寫範例 |
|---|---|
| 所有的搜尋引擎都可以檢索全部網站內容 | |
| 所有的搜尋引擎都不能檢索全部網站內容 | |
| 特定的搜尋引擎可以檢索全部網站內容 | 以Googlebot為例: |
| 特定的搜尋引擎不可以檢索全部網站內容 | |
| 特定搜尋引擎可以檢索特定的網站內容 | |
| 所有搜尋引擎都不能檢索特定路徑的網站內容 | |
| 特定搜尋引擎不能檢索特定路徑的網站內容 | |
| 所有搜尋引擎延遲爬取網站內容30秒 |
robots.txt語法備註:
- /:代表整個網站的所有網頁
- *:代表所有的搜尋引擎
最後提醒一下,通常不用特別設定「所有搜尋引擎都可以檢索網站所有內容」,因為這本就是搜尋引擎會自動執行的動作。
(四)robots.txt進階應用
阻擋特定的目錄與內容
Disallow: /tmp/
Disallow: /admin/
阻擋特定檔案類型爬取
Disallow: /*.gif$
「gif」可以更換成png、jpg等檔案類型,讓搜尋引擎知道哪些檔案不要爬取。
(五)遭到robots.txt封鎖的頁面該怎麼解除封鎖?
根據Google官方Search Console的說明,想要解除robots.txt的方法如下:
- STEP1:先透過robots.txt驗證工具或是Google Search Console,確認被robots.txt封鎖的頁面確實存在與位置
- STEP2:接著,直接修改robots.txt檔案即可;如果你是使用網站代管服務,因每家代管服務的方式不同,因此請直接根據代管服務供應商的說明文件進行修改。
✨想了解詳細的Google官方說明:解除封鎖受到robots.txt封鎖的網頁
(六)robots.txt Wordpress-Yoast教學
Yoast SEO對於使用Wordpress架設網站的人想必很熟悉,許多SEO的相關設定都可以透過Yoast這個擴充程式快速達成。
以下將教你如何利用Yoast設定robots.txt:
- STEP1:點擊左側工具欄的「工具」
- STEP2:接著,點擊進入「檔案編輯器」
- STEP3:最後將robots.txt程式代碼輸入,並按下儲存即可
✨如果想要深入了解WordPress SEO如何執行,推薦你閱讀此篇文章:WordPress SEO怎麼做?WP SEO教學、4大SEO外掛推薦

(七)3個robots.txt產生器推薦
如果你是看到程式代碼就頭痛的人,只要透過以下這3個robots.txt產生器,並按照只是點選想要的robots.txt指令,不用1分鐘程式代碼就生成囉!
- SEOptimer(英文介面)
- Ryte(英文介面)
- Chinaz robots.txt文件生成(簡體中文介面)
設定robots.txt Google注意事項
📍robots.txt注意事項-設定
- 建議使用文字編輯器,像是記事本、Notepad、TextEdit、vi和emacs等工具建立robots.txt檔案,而非文書軟體(例如Word),避免因符號不相容而在檢索時出現問題。
- 務必用內容必須以CR、CR/LF或LF分隔行列,否則Google會忽略。
- 儲存檔案時,必須選擇UTF-8編碼,並以純文字檔案格式儲存。
- 檔名必須命名為「robots.txt」,僅能使用小寫,否則恐遭爬蟲忽略。
- 目前robots.txt檔案的容量大小有強制規定,最多為500KB。超過此限制的內容將會被Google忽略。
📍robots.txt注意事項-放置、變更
- 為了讓Google正確辨識網站的robots.txt檔案指令,該檔案必須放在網站目錄的最上層,並且開放公開存取。
- 若Google無法辨識robots.txt檔案的內容,例如檔案格式錯誤或不支援,將會直接忽略指令。
- 若要更改網站robots.txt檔案,需更新檔案後重新提交至Google,以加速應用程式更新。
- Google收到robots.txt檔案變更後,生效時間不固定。如需加快生效,建議重新提交檔案以推進流程。
robots.txt vs meta robots|meta robots怎麼寫?
說到robots.txt就不能不提到meta robots,在搜尋引擎上,常常有人用「HTML meta robots」這個關鍵字查詢,因為meta robots的語法和HTML十分類似,那究竟meta robots和我們本篇的主題robots.txt有何差異呢?
(一)robots.txt vs meta robots比較表
robots.txt和meta robots最大的差異就在:
robots.txt是限制「檢索」,而meta robots則是明確的指令「不准建立索引」。
此外,設定meta robots也比較麻煩,必須在你不想被索引的網頁head標籤裡,透過手動輸入的方式進行設定。
| robots.txt | meta robots | |
|---|---|---|
| 主要功用 | 限制搜尋引擎進行特定網站內容的「檢索」 | 限制搜尋引擎進行特定網站內容的「建立索引」 |
| 撰寫方式 | 使用文字編輯器撰寫robots.txt後,上傳到網站 | 新增在該網頁的head標籤裡 |
| 程式代碼 |
(二)meta robots程式代碼解析
meta robots程式代碼常見的有6種,像是meta index follow等,以下將詳細介紹這6種程式代碼分別代表的意義為何:
| 程式代碼 | 定義 |
|---|---|
| meta name | 用於輸入搜尋引擎名稱 |
| content | 填寫網頁是否允許建立索引,下令meta noindex或是index nofollow等 |
| index | 如果是允許建立索引的頁面,便可下令meta robots index網頁 |
| noindex | 下令meta robots noindex就可以禁止搜尋引擎建立索引 |
| follow | 若網頁中加入其他網頁或不同網站的連結,若未指示「meta robots nofollow」,則Google可以追蹤該網頁上的連結 |
| nofollow | meta nofollow用於禁止追蹤該網頁上的連結,以防止分享自己的網站權重 |

(三)meta robots Examples 撰寫範例
📌meta robots index, follow
意指允許建立索引,且可以追蹤網頁內的連結。
然而其實沒有特別下者個meta robots的指令,根據搜尋引擎的習慣仍會這麼做,因此此設定的必要性較低。

📌meta index, nofollow
表示搜尋引擎可以建立索引,但不允許追蹤網頁的連結。

📌meta noindex, follow
不允許搜尋引擎建立索引,但可以追蹤網頁的連結。

📌meta noindex, nofollow
不允許搜尋引擎建立索引,也不可以追蹤網頁的連結。

robots.txt測試工具(robots.txt Tester)怎麼用?Google官方工具教學!
Welly SEO建議設定完robots.txt,一定要透過robots.txt測試工具進行檢測,確認是否真的成功封鎖了不想被檢索的網頁。
robots.txt測試工具在Google官方工具Search Console就有提供了,以下將針對Google官方的robots.txt測試工具進行教學:
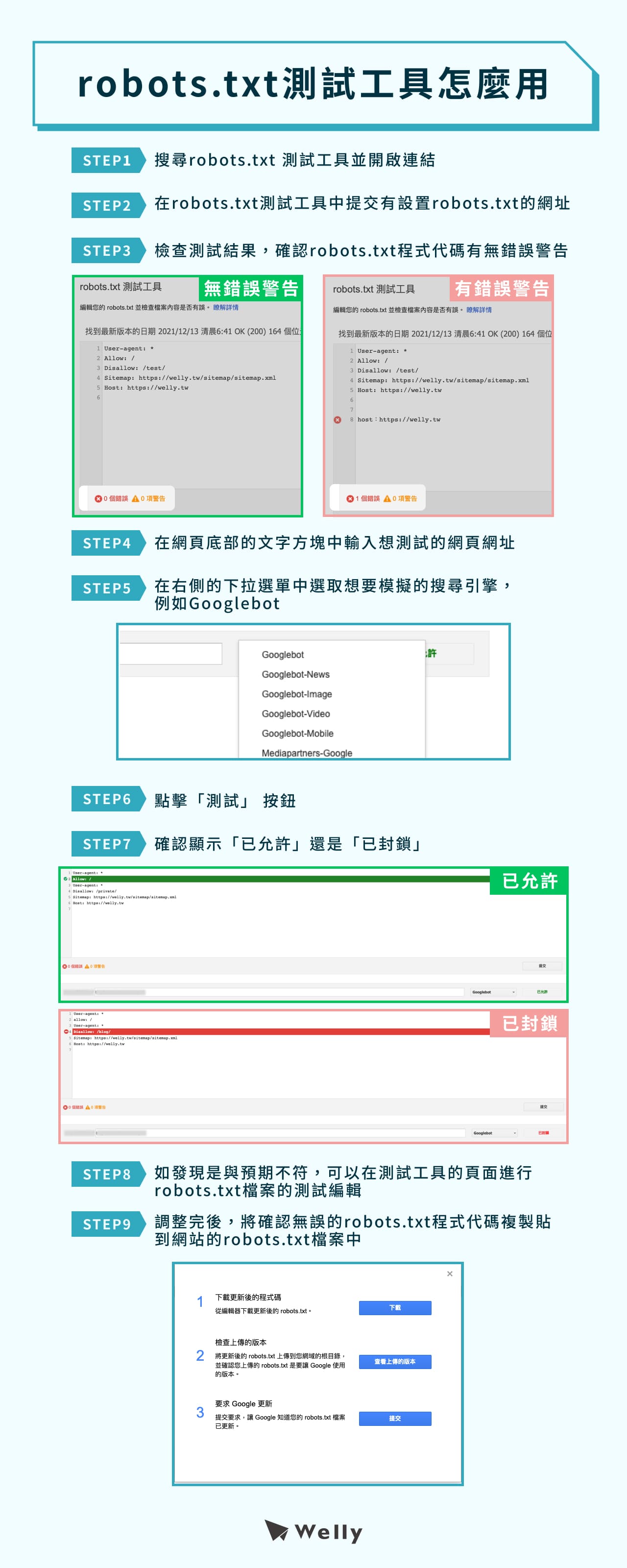
- STEP1:首先,搜尋robots.txt測試工具並開啟連結
- STEP2:在robots.txt測試工具中提交有設置robots.txt的網址
- STEP3:檢查測試結果,確認robots.txt程式代碼有無錯誤警告
- STEP4:在網頁底部的文字方塊中輸入想測試的網頁網址
- STEP5:在右側的下拉選單中選取想要模擬的搜尋引擎,例如Googlebot
- STEP6:點擊「測試」 按鈕
- STEP7:確認顯示「已允許」還是「已封鎖」
- STEP8:如發現是與預期不符,可以在測試工具的頁面進行robots.txt檔案的測試編輯
- STEP9:調整完後,將確認無誤的robots.txt程式代碼複製貼到網站的robots.txt檔案�中
使用robots.txt時,你可以控制搜尋引擎是否檢索你的網站,進而提高網站的SEO優勢。因此,適當編寫、更新你的robots.txt會是一個影響網站排名的重要元素。
以上就是robots.txt的介紹,如果您想要了解更多SEO資訊,或者想要獲取免費的SEO網站檢測,都可以透過下方黃色按鈕與Welly團隊聯繫!











